CoSNARKs Release (April 2025)
coCircom
Performance improvements
We have spent some time improving the performance of the collaborative Groth16 prover. This effort consisted of two main parts: (1) Multi-threading and (2) work reduction for replicated and Shamir secret sharing.
For the multi-threading improvements, this was mostly utilizing rayon whenever possible, even more than ark-groth16 is using it in the background, since the low-level operations like MSMs or FFTs do not perfectly utilize parallelization, it sometimes makes sense to parallelize several MSMs as well.
For the work reduction efforts, we have an article on Core detailing the main ideas: https://blog.taceo.io/honest-majority-mpc-for-cosnarks/. As a quick summary, we can utilize the fact that for these types of secret sharing schemes, after doing a multiplication, one can perform additional linear operations on the result of the multiplication before needing to communicate with other parties. This enables communication savings (instead of communicating a vector of N field elements after a element-wise multiplication, we can do an MSM with public points (a linear operation) and only then communicate the result, which is now a single field element). Furthermore, for replicated secret sharing we can use this technique to work on non-replicated shares for many operations, cutting down computation costs by a factor of two. Finally, for Shamir sharing in the 3-party case, we have also described and implemented a method to generate the correlated randomness needed without any communication required between the parties.
Benchmark results
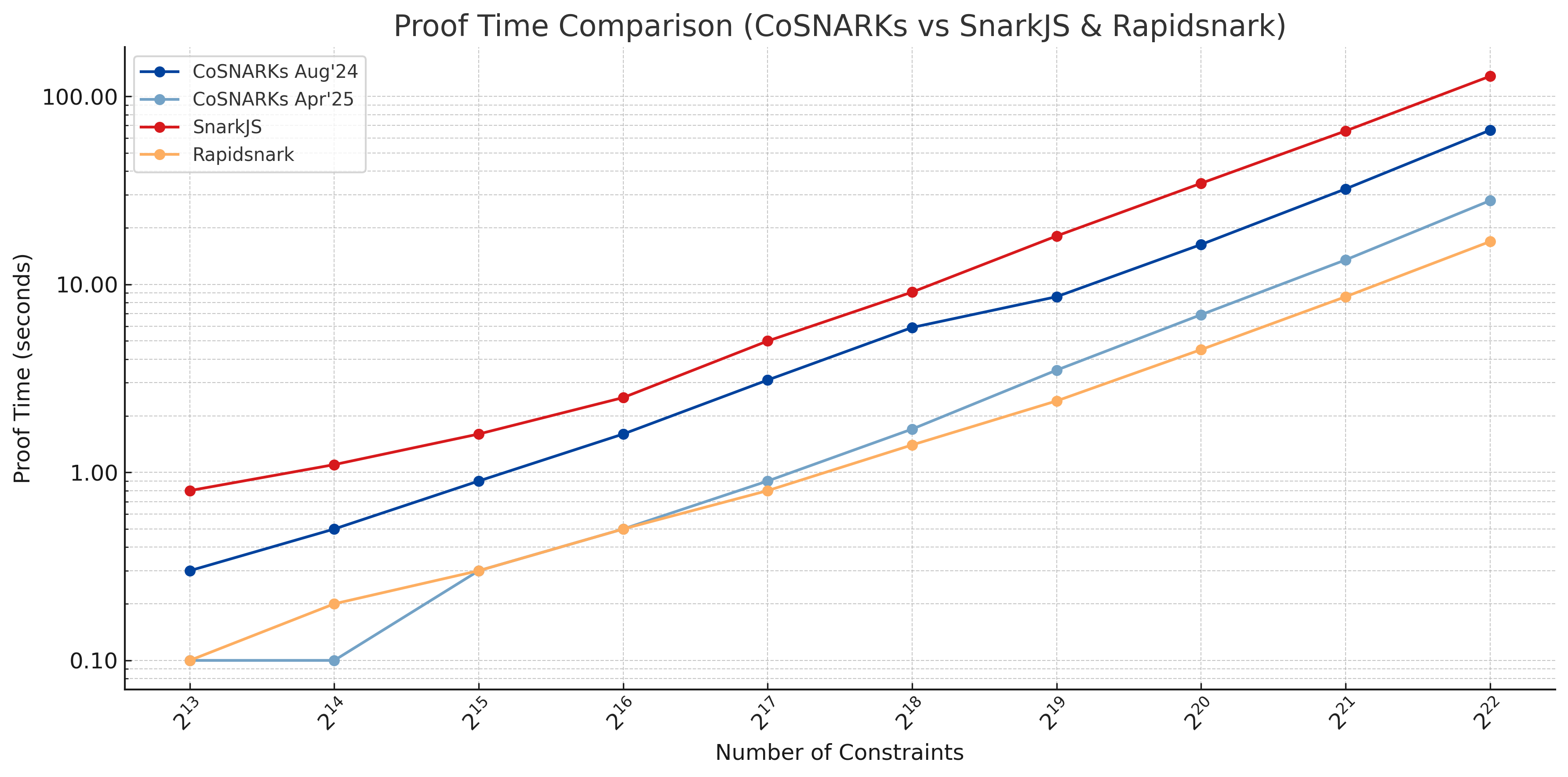
To quantify these improvements, we benchmarked the latest version of the coSNARK prover (as used in coCircom) against its previous release from August 2024, as well as against SnarkJS and Rapidsnark. The chart below shows the time taken to generate Groth16 proofs across a range of constraint sizes from to . As the results indicate, the April 2025 release is significantly faster, with up to x reduction in proof time compared to August 2024 and substantially better performance than SnarkJS across all sizes. While Rapidsnark remains the fastest in absolute terms, coCircom now operates well within the same performance envelope, with the added benefit of being MPC-compatible. Many circuits used by leading ZK applications fall around the -constraint range and hence can achieve sub-second proving times.
ark-groth16 compatibility
Our co-groth16 library is now also compatible with the libsnark-specific R1CS to QAP reduction that ark-groth16 uses by default. In the past, we implemented the reduction that Circom used only, now both of them are available. The co-circom binary is still only using the Circom reduction since it is intended to be analogous to the normal Circom workflow.
Batched Circom witness extension
We started basic efforts to support a batched witness extension, where multiple witness generation instances for the same circuit can be processed at the same time. Since the witness generation step suffers the most from circuit depth issues and a general lack of multi-threading support, this batched variant leads to large performance gains. For some example circuits we saw that executing 10 or 100 witness extensions in a batched form essentially adds no overhead compared to doing a single witness extension in MPC.
coNoir
Upgrade to barettenberg 0.82.3
The main change for coNoir was the bump to barettenberg 0.82.3, which brought a significant number of changes to the underlying proof systems.
Performance improvements
We also started a line of work to improve the performance of the collaborative UltraHonk prover that is used in coNoir. Since we rewrote the prover in Rust, we started by focusing on compatibility first, and are now tracking performance. Basic efforts have already brought 10-20x improvements for the execution of the sumcheck protocol in MPC, with reduction of MPC communication rounds being the largest gain. We are working on other areas as well and will also introduce a lot more multi-threading capabilities in the future.